Model Selection and Cross-Validation
In machine learning, model selection is a critical step that involves choosing the best model from a set of candidate models. A key component of this process is cross-validation, which helps us assess how well our models generalize to unseen data, typically referred to as the validation and test sets. Here, validation set is used to tune the hyperparameters of our model, while the test set is used to evaluate the performance of our model.
The Importance of Robust Cross-Validation
Robust cross-validation is essential for accurate model performance evaluation for several reasons:
- Generalization: It helps estimate how well a model will perform on unseen data, which is extremely important for real-world applications.
- Overfitting Detection: Cross-validation lets us know if a model is overfitting the training data.
- Model Comparison: It provides a standardized way to compare different models or hyperparameter configurations.
- Data Efficiency: It allows us to use our entire dataset for both training and validation, which is particularly valuable when data is limited.
Common Cross-Validation Techniques
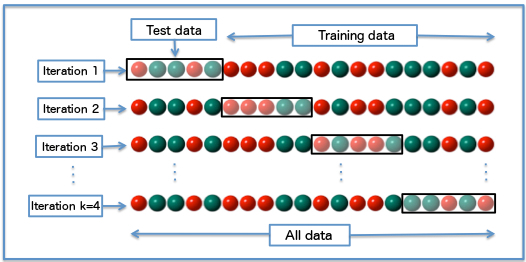
K-Fold Cross-Validation
K-Fold CV is one of the most widely used techniques:
- The dataset is divided into K equal-sized folds.
- The model is trained K times, each time using K-1 folds for training and the remaining fold for validation.
- The performance metric is averaged across all K iterations.
Advantages: - Uses all data for both training and validation - Provides a robust estimate of model performance
Disadvantages: - Can be computationally expensive for large datasets or complex models, especially if we are also performing hyperparameter optimisation
Source: Wikimedia Commons.
{kind=link}
Stratified K-Fold Cross-Validation
Stratified K-Fold CV is similar to K-Fold CV, but it ensures that the proportion of samples for each class is roughly the same in each fold as in the whole dataset. This is particularly important for imbalanced datasets.
Advantages: - Preserves class distribution in each fold - Useful for imbalanced datasets
Disadvantages: - Can be more computationally expensive than K-Fold - Requires class labels to be known beforehand
Drug Stratified Split
Drug Stratified Split is a custom cross-validator that we have implemented for our baseline modelling pipeline. This was based on the implementation in Ma et al., 2023. It ensures that each drug is represented in both training and test sets. This is particularly important for drug repurposing, where the same drug should not be used to both treat and validate a disease.
Here is a snippet from the original publication:
The post-processed drug–disease pairs... are split into training, validation, and test sets where the drug–disease pairs of each unique drug are randomly split according to a ratio of 8/1/1. For example, let’s say drugA has 10 known diseases that it treats (e.g., drugA–disease1, …, drugA–disease10), 8 pairs are randomly split into the training set, 1 pair is to the validation set, and 1 pair to the test set. With this data split method, the model can be exposed to every drug in the training set...
Advantages: - Ensures each drug is represented in both training and test sets - Useful for drug repurposing
Other Cross-Validation Techniques
While K-Fold and Stratified K-Fold are the most common, other techniques include:
- Leave-One-Out CV: Extreme case of K-Fold where K equals the number of samples.
-
Time Series or Time Split CV: Specific for time-series data, respecting temporal order. We have implemented a proof-of-concept (POC) version of this in our pipeline. This is particularly useful when we want to build a model using knowledge up to a given point in time, and then test it on knowledge that became available after we built our model. This approach allows us to simulate how our model would perform in real-world scenarios where we're predicting future outcomes based on past data.
-
Nested CV: Used when you need to tune hyperparameters and estimate generalization error.
Implementing Robust Cross-Validation
To ensure robust cross-validation:
- Use multiple runs: Repeat the CV process multiple times with different random seeds.
- Choose appropriate K: Generally, 5 or 10 folds are common, but this can vary based on dataset size.
- Stratify when necessary: Use stratified CV for imbalanced datasets.
- Consider problem-specific constraints: e.g., group-based CV for related samples- for example drugs and diseases in our use case.
Hyperparameter Tuning and Model Selection
Cross-validation plays a crucial role in hyperparameter tuning. Techniques like Grid Search CV or Random Search CV use cross-validation to evaluate different hyperparameter combinations and select the best performing model. We have implemented our own version of a Bayesian hyperparameter optimisation algorithm.
Leveraging Scikit-learn's Model Selection Library
We have included functionality in our pipeline to take advantage of methods available within the scikit-learn model selection library. This allows us to easily implement various cross-validation techniques and model selection methods, including:
KFoldandStratifiedKFoldfor standard and stratified k-fold cross-validationGridSearchCVandRandomizedSearchCVfor hyperparameter tuningcross_val_scoreandcross_validatefor easy evaluation of models, in addition to our custom suite of evaluation metrics
By leveraging these tools, we can efficiently implement robust cross-validation strategies and automate much of the model selection process.
Interpreting Cross-Validation Results
When interpreting cross-validation results: 1. Look at both the mean performance and its variance across folds and repeats. 2. Be cautious of overly optimistic results, especially with small datasets. 3. Consider the practical significance of performance differences, not just statistical significance or minor differences.
Limitations of Cross-Validation
While cross-validation is a powerful tool, it's important to be aware of its limitations: 1. It may not capture all real-world variability, especially for time-dependent data. 2. For small datasets, the variance of CV estimates can be high which makes repeating the CV process with different random seeds and taking an average of the results more important. 3. It may not be suitable for all types of data (e.g., certain time series data).
Conclusion
Robust cross-validation is a key component of reliable model selection and performance estimation. By carefully choosing and implementing the right CV technique, we can build more trustworthy and generalizable models for drug repurposing and other critical applications in healthcare and beyond.
References
- Chunyu Ma, Zhihan Zhou, Han Liu, David Koslicki, KGML-xDTD: a knowledge graph–based machine learning framework for drug treatment prediction and mechanism description, GigaScience, Volume 12, 2023, giad057, https://doi.org/10.1093/gigascience/giad057